Hey,
some time ago I got curious about whether gRPC would be something suitable for sending files over the wire.
One of its goodness is the native support of streams, so, why wouldn’t it be?
A service and a message
To get the idea going, I took the approach of defining a minimum viable service, one that takes some chunks and then, once received, counts how many bytes of the actual content has been received.
These chunks were defined like the following:
message Chunk {
bytes Content = 1;
}
As the service takes this as a stream, we can define it like so (see cirocosta/gupload/messaging/service.proto):
service GuploadService {
rpc Upload(stream Chunk) returns (UploadStatus) {}
}
enum UploadStatusCode {
Unknown = 0;
Ok = 1;
Failed = 2;
}
message UploadStatus {
string Message = 1;
UploadStatusCode Code = 2;
}
To better visualize what’s going on, we have the following:
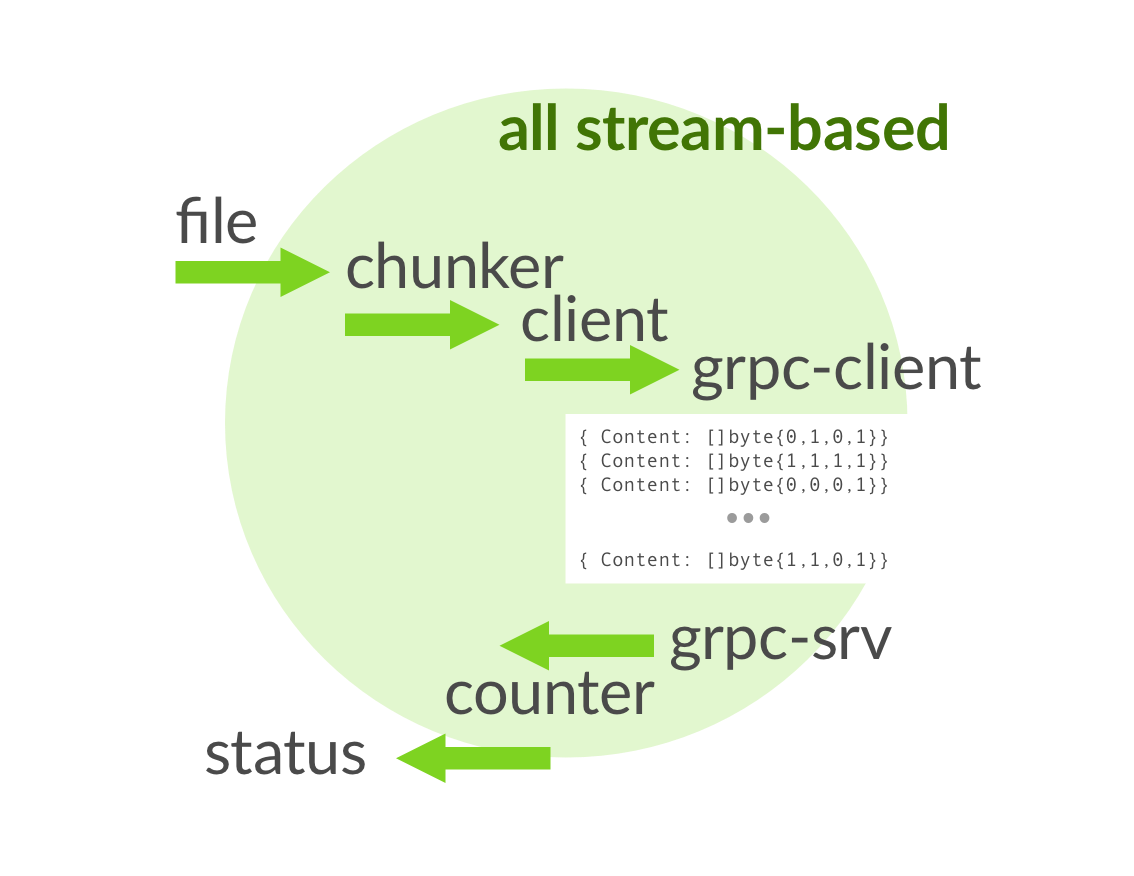
In essence, this means that we get a file handle and once the connection is started, we start splitting its contents in chunks and sending these fragments as Chunk messages over the gRPC connection that got established. Once messages arrive at the server, we unpack those messages (which contains the raw bytes in the Content field. After all the transmission has been finalized, an UploadStatus message is sent to the client, and the channel is closed.
You can check the code in cirocosta/gupload.
The gist of the client is, with some parts removed for brevity, the following:
func (c *ClientGRPC) UploadFile(ctx context.Context, f string) (stats Stats, err error) {
// Get a file handle for the file we
// want to upload
file, err = os.Open(f)
// Open a stream-based connection with the
// gRPC server
stream, err := c.client.Upload(ctx)
// Start timing the execution
stats.StartedAt = time.Now()
// Allocate a buffer with `chunkSize` as the capacity
// and length (making a 0 array of the size of `chunkSize`)
buf = make([]byte, c.chunkSize)
for writing {
// put as many bytes as `chunkSize` into the
// buf array.
n, err = file.Read(buf)
// ... if `eof` --> `writing=false`...
stream.Send(&messaging.Chunk{
// because we might've read less than
// `chunkSize` we want to only send up to
// `n` (amount of bytes read).
// note: slicing (`:n`) won't copy the
// underlying data, so this as fast as taking
// a "pointer" to the underlying storage.
Content: buf[:n],
})
}
// keep track of the end time so that we can take the elapsed
// time later
stats.FinishedAt = time.Now()
// close
status, err = stream.CloseAndRecv()
}
For the server, almost the same - receive the stream connection and then gather each message:
// Upload implements the Upload method of the GuploadService
// interface which is responsible for receiving a stream of
// chunks that form a complete file.
func (s *ServerGRPC) Upload(stream messaging.GuploadService_UploadServer) (err error) {
// while there are messages coming
for {
_, err = stream.Recv()
if err != nil {
if err == io.EOF {
goto END
}
err = errors.Wrapf(err,
"failed unexpectadely while reading chunks from stream")
return
}
}
END:
// once the transmission finished, send the
// confirmation if nothign went wrong
err = stream.SendAndClose(&messaging.UploadStatus{
Message: "Upload received with success",
Code: messaging.UploadStatusCode_Ok,
})
// ...
return
}
With that set we can start measuring the transfer time.
Scenarios
To keep the transmission running for little while I picked a payload of 143M (.git of github.com/moby/moby as an uncompressed .tar).
The server and client shared the same host (macOS 16 GB 1600 MHz DDR3, 2.2 GHz Intel Core i7 Retina, 15-inch, Mid 2015) and communicated via loopback.
Apparently, this is not the best way of testing this kind of stuff, but I think the overall idea is still valid anyway.
I wanted to understand how changing the size of the chunks would affect the overall transmission time. I hypothesized that there was going to exist a significant number between a big chunk and a small chunk that would be optimal for the transmission.
With that said, I created the following test script:
#!/bin/bash
main () {
# for every chunk size in
# "16, 32, 64, 128 ... 2097152 (2MB)"
for k in $(seq 4 21); do
# run the upload 50 times
for i in $(seq 1 50); do
upload_file_via_grpc_tcp_compressed "$k"
done
done
}
upload_file_via_grpc_tcp () {
local number=$1
printf "$number,"
gupload upload \
--address localhost:1313 \
--chunk-size $(./shift 1 $number) \
--file ./files.tar
}
main
shift is just a little program that performs the bit shifting of two arguments:
int main(int argc, char** argv) {
// ... validates argc and argv
int number = atoi(argv[1]);
int shifts = atoi(argv[2]);
printf("%d\n", (number << shifts));
return 0;
}
which means that our test case would produce a CSV: <number_of_bitshifts>,<time>, for instance:
4,28418808431
4,31305514409
4,30451840141
...
5,16610844861
5,15894009998
...
6,8175781898
6,8074899000
...
Having those two columns, we can then put it in Excel, create a pivot table and then gather insights about the data.
Results
I let that script run for a while, here are the results:
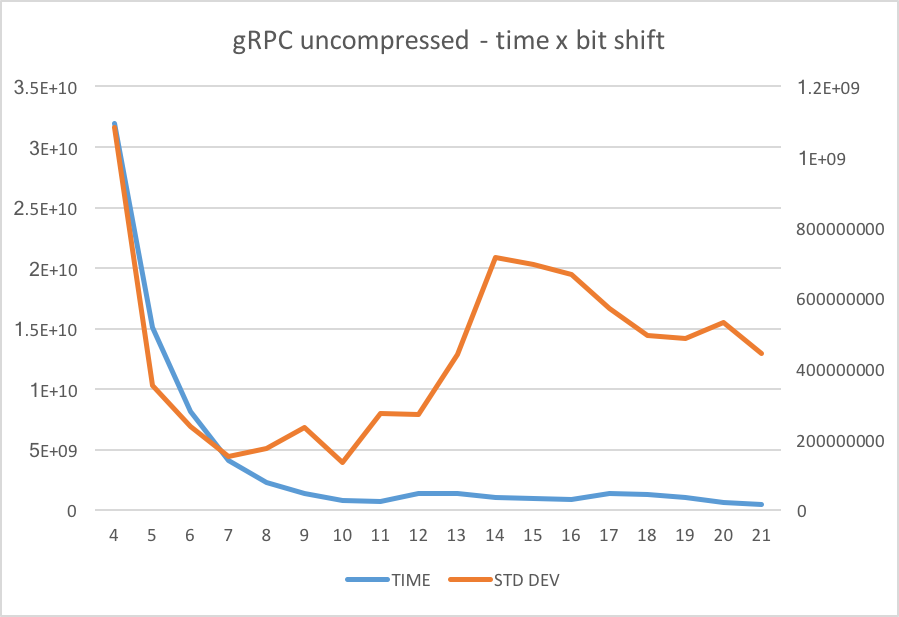
From the results, it looks like if we have a tiny chunk size (16, 32, 64 and 128), we can’t deliver too much over the network. That’s clear via the CPU usage: I was getting close to 200% on each process (client and server), clearly seeing the transfer being bottlenecked by the CPU, which is not the desired.
As we move to more significant values it becomes evident that the time to transfer the data falls considerably, but we start seeing a big variance in the times - sometimes it was performing pretty well, sometimes it was pretty bad.
It seems like at 1024bytes (1KB) we have a decent throughput.
I was expecting something like 32KB: (1 << 15) to be the most optimal but it looks like it’s one of the worst scenarios regarding variance.
Maybe that’s something that’s only observed when running both client and server on the same machine … I’m not sure.
As in this scenario I wasn’t making use of TLS I thought that perhaps the underlying gRPC would not be using HTTP2 (I need to confirm this!); thus I could probably get some different results running with TLS enabled.
That wasn’t the case though:
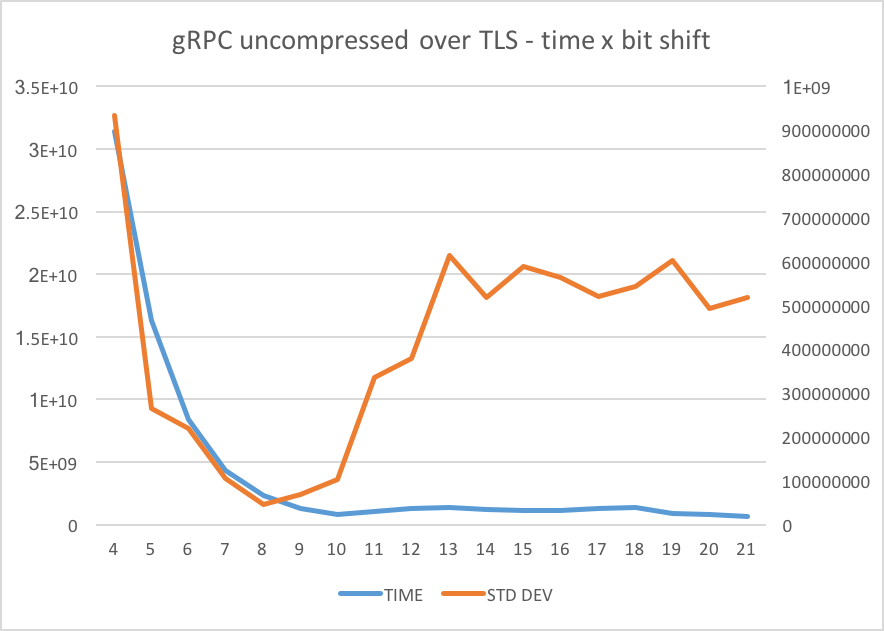
The variance is shifted a bit but, still, very close results.
Comparing with plain HTTP2
I wanted to have a baseline to compare these results, so I made client and server a simple interface that other types of clients and servers could implement.
With that set I created a HTTP2 client and server that you can check out at the repository - https://github.com/cirocosta/gupload under ./core/client_h2.go and ./core/server_h2.go.
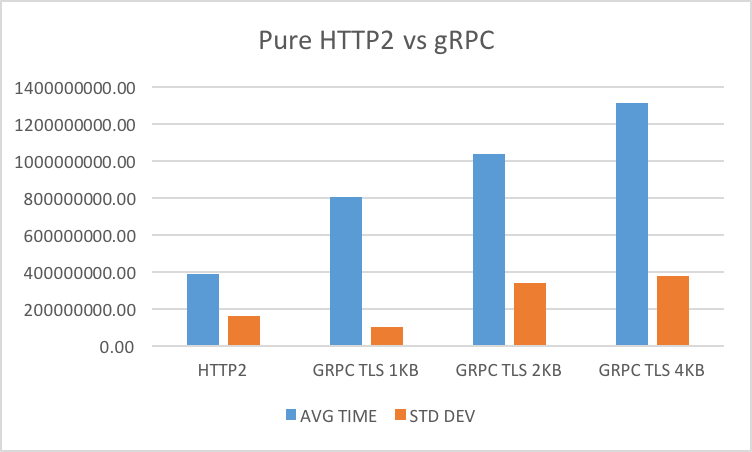
I think it’s evident that for this workload a raw transfer of bytes over http2 should be faster than the gRPC one as there’s no encoding and decoding of messages - just raw transmission of data.
Closing thoughts
I didn’t want to draw many conclusions from this but just make clear in my head that it’s critical to understand what’s your workload and how the underlying transport works to get the best results possible. It’s common to get caught in fallacies of distributed computing and just start assuming things. This week I tried to pretend less and test more.
If you liked this article, there’s another blog post I wrote about buffering where I explore where buffering takes most effect, and it’s very interesting to see how different network conditions affect transmission.
If you’ve got interested in this article, you probably should also check out The Site Reliability Workbook - Practical Ways to Implement SRE.
It’s about practical examples of Google’s experience, and the internal gRPC equivalent (Stubby) as well as GRPC itself is part of it.
Again, it was all “loopback-based” so take it with some salt.
If you want to get the results, here’s the Excel file: grpc-uploads.xslx.
Let me know if I got anything wrong; I’d love to understand more about it and see what you think.
Have a good one!
finis