Hey,
Quite a while ago, when we were putting hush-house up (an environment where rather than using BOSH to deploy Concourse, we use plain Kubernetes), it really bugged me that our streaming performance would be so bad after having just finished downloading stuff at some pretty high rates (see concourse/hush-house#49):
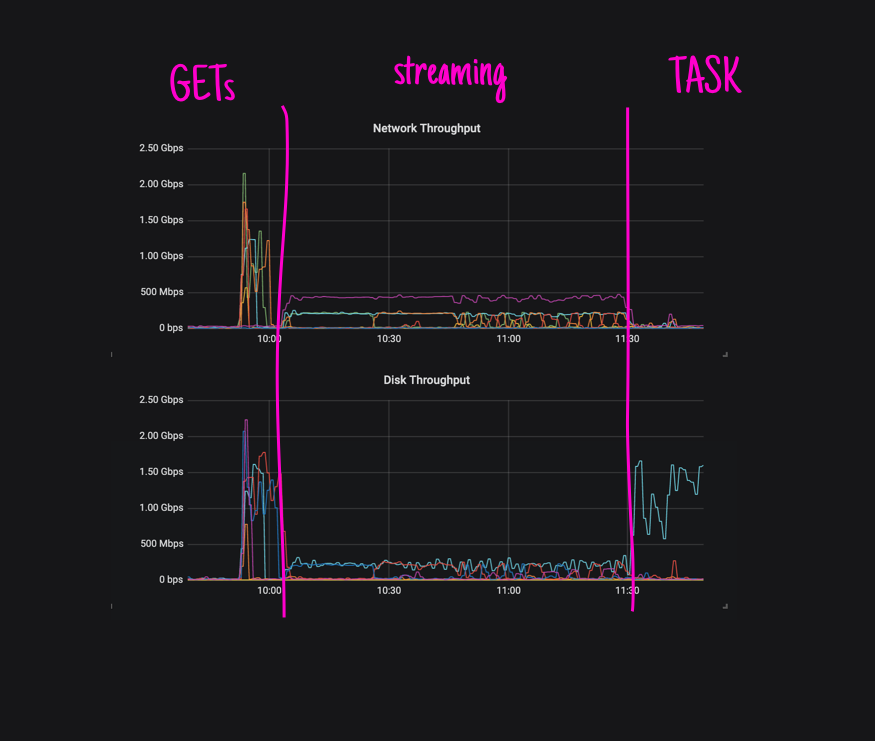
Although we all knew that streaming could be improved, we have never really took the time to measure (afaik) that in a scenario where it’d be obvious that something needed to change - in our case, measuring the impact of serially streaming artifacts in a job comprised of 100s of inputs was a big motivator.

(yeah, that’s not even the entire visualization of the job)
Before we introduced parallel input streaming and started leveraging zstd compression to send bits from one worker to another, the main step of the job in the pipeline above would just take forever to initialize - after all of those resources were fetched to a various workers, we’d then start the process of sending all of those bits to a worker, and not only would that happen one at a time, it’d also be limited by the compression that was performed in a single-thread (for each artifact), regardless of how vertically big the machine was.
Now, with those unlocked (parallel compression + concurrent streaming), that all looked much better (at the expense of some extra CPU utilization):
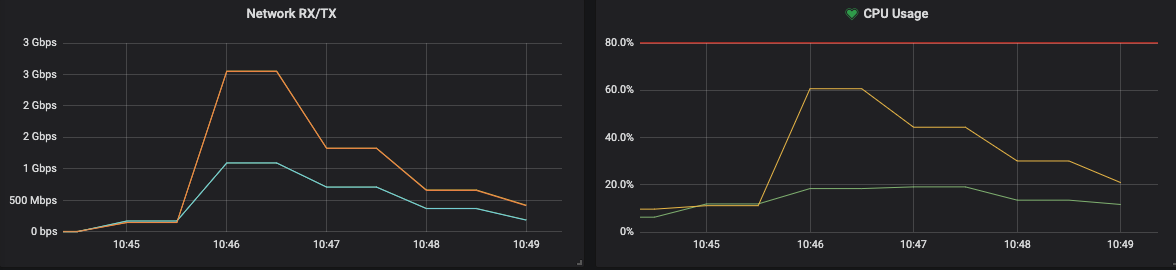
While those improvements were great, I think we can do even better, at least in some (very common) scenarios: where workers can talk directly to each other.
For instance, consider the following (partially defined) pipeline composed of
three steps, where the two tasks use repository as an input.
jobs:
- name: validate
plan:
- get: repository
tags: [worker-1]
- in_parallel:
- task: lint
tags: [worker-2]
file: ci/lint.yml
- task: test
tags: [worker-3]
file: ci/test.yml
Assuming that each worker is tagged with worker-N, that’d mean that the
following streaming would necessarily occur:
worker-1 -------> worker-2
|
*-----------> worker-3
As worker-1 was the worker that ran the get
for the repository resource (let’s say that this was based of the
git-resource resource type),
those bits that were cloned need to be streamed to those other two workers so
they can do their work on top of the repository that was retrieved.
What’s not shown above though, is that there’s an intermediary (in some cases,
two!) that sits right between worker-1 and worker-2: there’s a web node
right there.
i.e., it actually looks like this:
worker-1 ----> web-N ----> worker-2
and, in the worst case, even this:
worker-1 ---> web-N ---> web-M ---> worker-2
But, I think there might be a way of getting around that … for some cases (or, perhaps, most cases?)
Before, let’s remind ourselves of how a Concourse installation looks like.
concourse architecture
In order to be continuously doing things as you wish, Concourse is made up of three components:
web: responsible for scheduling, gc, serving the UI + API, and worker registrationworker: dealing with running containerspostgres: persistence
i.e.:
INTERNET CONCOURSE INSTALLATION
/
/ POSTGRES.......................
/ .
/ . db: concourse------.
/ . |
/ . |
/ . |
/ |
/ |
/ |
/ |
/ WEB.............................
/ . |
/ . |
user ----+--------.---> atc ---------------*
/ . tsa <-----------------.
/ . |
/ |
/ |
/ |
/ |
/ WORKER......................+...
/ . (ssh) |
/ . beacon----------------*
/ . baggageclaim :7788 (forwarded)
/ . garden :7777 (forwarded)
/ .
/ .
/
The way that those workers get registered is quite handy:
tsalistens on a given port (2222 by default)- an operator whitelists the worker’s public key on
tsa - the worker comes to
tsa(reachable to the worker), and then performs the handshake, having the private key that matches that public key that was whitelisted before - the worker asks
tsato do port-forwarding to its ports (7788 and 7777), thus, making the worker available to any other web notes that can reach web’s ports.
i.e.
TSA WORKER
1. gets up w/ whitelisted
pub keys
2. connects against TSA at reachable
address
~~~ conn established ~~~
3. requests port-forwarding for garden
and baggageclaim
4. listens on two extra ports
to proxy conns to the worker
Once that’s all done, a given actor can reach, let’s say, worker1’s
baggageclaim server by reaching TSA’s ephemeral port that is forwarding requests
through SSH to that worker that can either live in the same datacenter as
itself, or, in someone’s desk (having the traffic from tsa to worker
encrypted).
in a library
AGENT
| AZURE
|
*-------------> tsa1 --- (ssh) -----------> bagaggeclaim123
AWS
This becomes very useful when it comes to having multiple web nodes, with workers registering against any of them - as long as one web node has access to the other, we can access workers' services regardless of where they live.
For instance, it enables the following topology to exist:
DC1 \ DC2
\
\
web1--------------...-----------web2
| \ |
| \ |
worker1 \ worker2
(lines represent connectivity)
In this scenario, if web1 wants to place a container in worker2, it can do
so because it can reach web2’s port that forwards traffic down to worker2.
While it’s great that we’re able to allow those scenarios to exist, it turns out that (and now, I’m just guessing), the majority of the big Concourse deployments out there are not really set up in that way - they mostly have the majority of their workers colocated in the same datacenter, having a less significant part of workloads sitting somwhere else (or some other form of large collocation).
DC1 OFFICE (or, DC2?)
web-1 --.
web-2 --+---.
| |
| |
worker1--* *--a-weird-darwin-worker
worker2--* *--a-random-windows-worker
worker3--*
|
.. |
|
worker34-*
Thus, what if we made that information available to the web nodes, i.e., that information that a set of workers live in the same area, and can be accessed directly, and then in those cases, let them stream directly from one to another?
But before we jump into that train, if we went with towards that direction, what would we gain?
the cost of the intermediary web node
The work of proxying things is definitely not free, but, how costly is that, exactly?
We can’t just say that it’s just the cost of forwarding packets from one machine to another and treat it like a regular proxy, because there’s defininitely more than just that - packets directed to a worker flow through SSH, thus, at userspace, all of those packets need to be encrypted (not only from the worker side, but also from the web side - those two sessions are completely independent).
WORKER-1 -----(ssh)----> WEB ------(ssh)-----> WORKER-2
This means that we can’t1 just use nice tricks that keep all packet forwarding
within the kernel (like sendfile(2) for non-encrypted transmission on Linux,
or a combination of that and ktls on freebsd.
1: well well, actually, I guess we could do some sendfile(2) + wireguard
combination, keeping all within the kernel on Linux, but let’s scratch that for
now.
To be able to get some practical measurements, I set up a little project that contains just what we need for this (copying most of the stuff from the Concourse code) - ssh-proxy:
- an SSH server that accepts port-forwarding requests (just like
tsa)- and, rightfully forwards connections as they come
- an SSH client that requests port-forwarding (just like
worker)- and, rightfully forwards connections as they come
In its most basic form, it looks like this:
(ssh-proxy)
curl --------> server:1234 ---> client ---> application:8000
(ssh-proxy)
/-----------------/
SSH
Leveraging pretty much the same codebase as Concourse, we can be very close to the real performance implacations of that SSH forwarding when transmitting bits (we’d be even using the same stack).
the experiment
The hypothesis that we wanted to disprove was:
-
there’s no significant difference in terms of throughput having an intermediary transferring the data on top of an SSH connection.
-
there’s no signiificant difference in terms of CPU utilization having an intermediary transferring the data on top of an SSH connection.
While we could (probably, should?) go all scientific on how to properly formulate “significance”, I’d be convinced that a 50% difference would be enough.
In terms of setup, I settled on three scenarios:
-
the “absolute best” (plain zero-copy direct TCP streaming) :
VM1 VM2 cg tx -----------------------> cg rx /-----------------------------/ no more than TCP -
a TLS-based direct streaming
VM1 VM2 tlssample --------------------> tlsssample -server /-----------------------------/ no more than TLS -
SSH-proxied streaming
VM1 VM2 cg tx cg rx <-----------. | | *-> ssh-proxy server ---------> ssh-proxy client -* /---------------------------/ SSH
ps.: the cg that I mentioned up there is chicken-gun, a little tool I created to
very efficiently send loads of data very quickly by leveraging splice(2).
To collect data about them, I went with node_exporter on the hosts, having the data being collected by a third (external) VM.
results
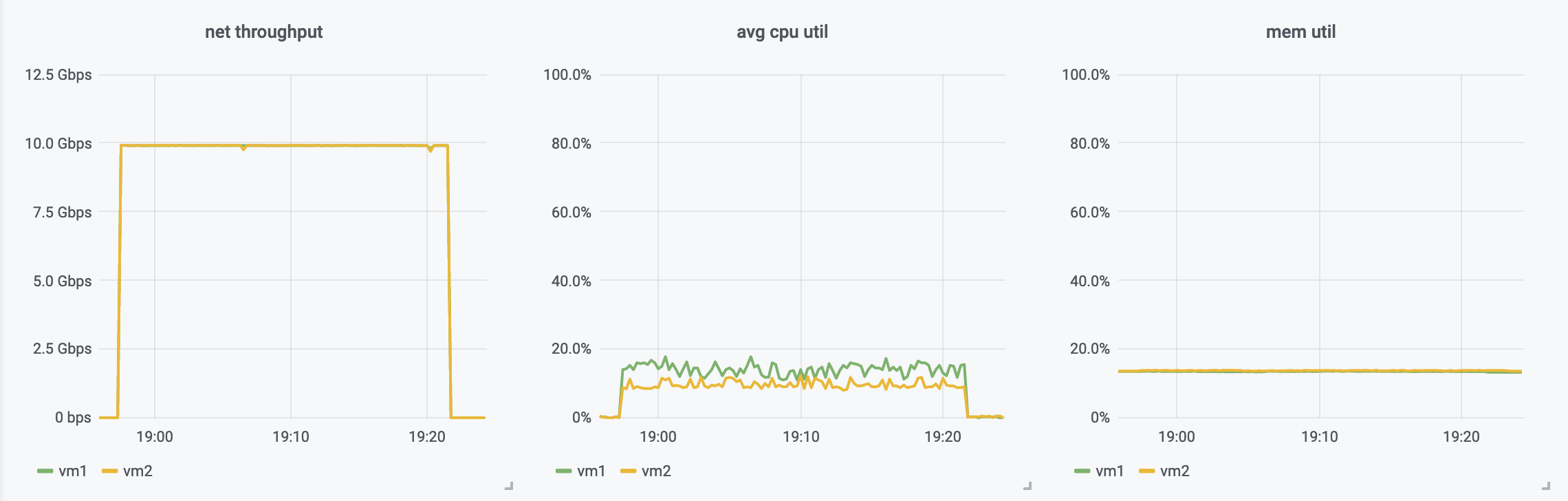
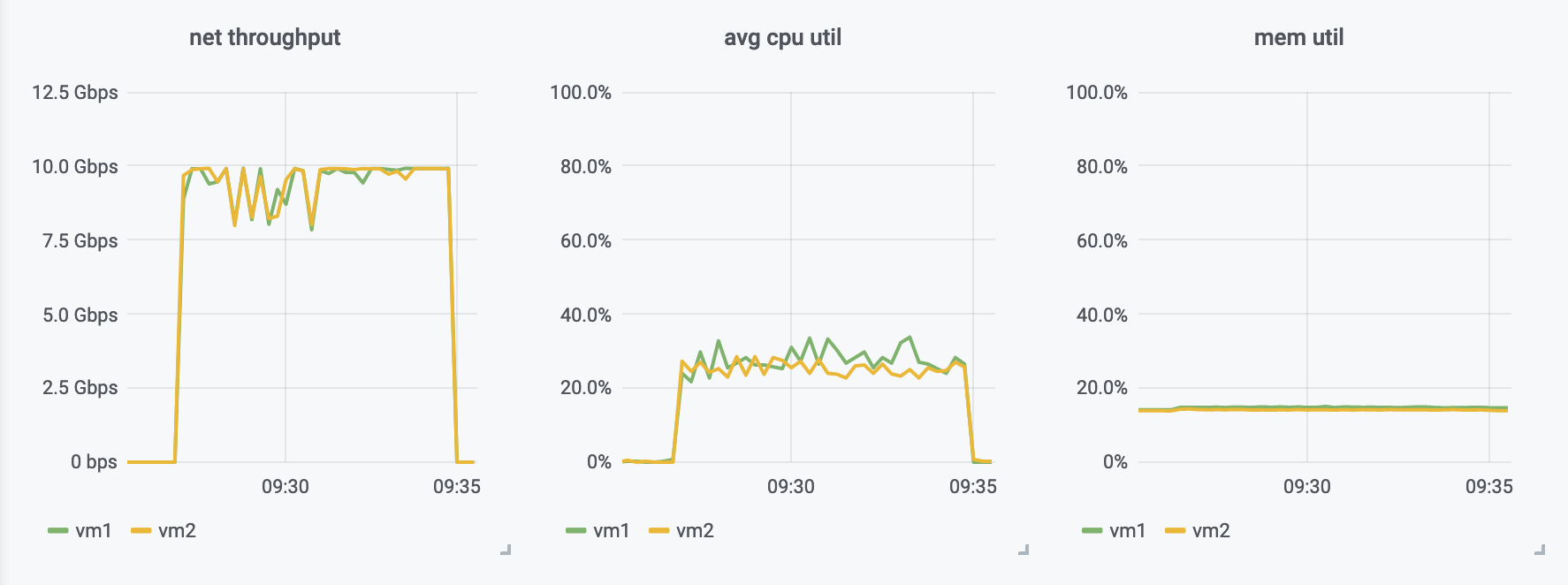
Having those three scenarios running for a while, I was very happy to see that with direct TLS we are able to get throughput that’s very similar to direct zero-copy streaming (naturally, paying the encryption etc with CPU, but still, pretty good!).
The ssh-proxy scenario was as expected - way less throughput than the other scenarios.
zero-copy direct TCP streaming
direct TLS
proxied through SSH
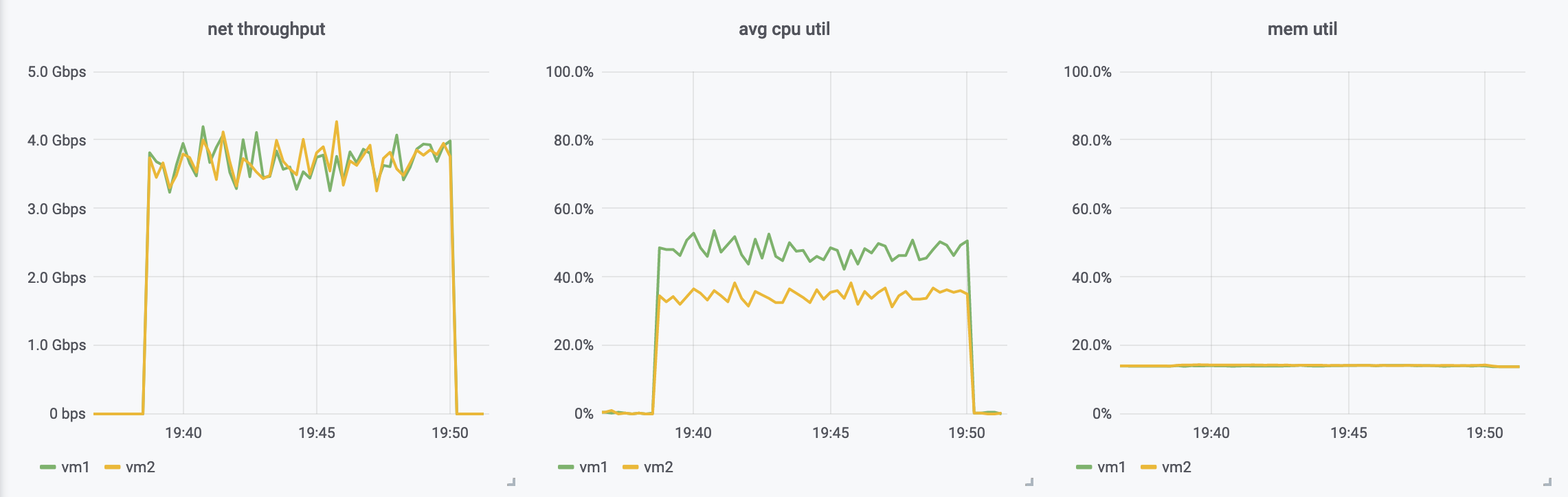
With thouse results in mind, let’s see somethinig that we could do.
an idea
The idea is to get rid of that intermediary whenever ATC “sees fit”, letting a worker stream the data directly from itself towards the other node.
As that’d mean that a worker would need to directly reach the other, ATC needs to know how that topology looks like.
.....ATC
.
. "hey, stream this volume to `worker2`
(1).
.
.
worker1-----------------(2)---->worker2
But, naturally, a cluster can be formed with workers from all sorts of different networks, with all sorts of different connectivity.
Thus, on worker registration, these would:
- advertise which “zone” their part of
- advertise which address they can be reached at within that zone
If you’re familiar enough with Concourse, you might realize that there’s
actually a quite similar thing already there - look at /api/v1/workers and
you’ll get something like the following:
{
"addr": "10.11.3.25:35485", .... hmmmm
"baggageclaim_url": "http://10.11.3.25:36277", .... hmmmmmmm
"active_containers": 150,
"active_volumes": 737,
"active_tasks": 0,
"resource_types": [
{
"type": "git",
"image": "/usr/local/concourse/resource-types/git/rootfs.tgz",
"version": "1.2.3",
"privileged": false,
"unique_version_history": false
}
],
"platform": "linux",
"tags": null,
"team": "",
"name": "worker-worker-1",
"version": "2.2",
"start_time": 1570883471,
"ephemeral": false,
"state": "running"
}
Buuuut, the reality is that those are actually the addresses at which they can be reached from TSA (i.e., those are the addresses of the TSA nodes that they registered against).
Given that this would still be valuable for the case when zones don’t match (i.e., when there’s no possibility of direct connectivity between two workers), we’d need to actually add something.
{
"active_containers": 150,
"active_volumes": 737,
"addr": "10.11.3.25:35485",
"baggageclaim_url": "http://10.11.3.25:36277",
+ "baggageclaim_peer_url": "http://10.33.33.1:7777",
...
}
That said, baggageclaim (the component in the workers that’s responsible for
volume management) then implements a new endpoint (/volumes/:handle/stream-to)
that, when touched, makes it initiate a connection against a given worker (that
it can reach), sending the data directly.
ATC
.
.
. PUT /volumes/:handle/stream-to
. Host: worker1
. Body: {dest: "worker2"}
.
.
*---->bc worker1
.
. PUT /volumes/:handle/stream-in
. Host: worker2
.
*--------> bc worker2
For the cases where a given streaming pair (source and destination) doesn’t have a match for their zones, regular streaming through web nodes would take place.
Note that we don’t necessarily need to go with “this one pushes to the other one” - the other way around could work just as well (maybe even better? it’d see a lot more like “hey worker, go get your bits over there, and, btw, here are your credentials to do so”).
is this just direct worker registration?
Differently from the direct worker registration that we used to do before (see
remove support for direct worker registration from the TSA,
the idea here is that we’d have literally no traffic flowing throug the web
nodes.
When we had direct worker registration, the workers table would get filled
not with address of the TSA ephemeral port, but rather, the address of
baggageclaim directly.
In that scenario though, we were still proxying traffic through the web nodes:
atc
--> establish `stream-in` conn w/ baggageclaim1
--> establish `stream-out` conn w/ baggageclaim2
io.Copy(streamIn, streamOut)
By having the ability to make a given baggageclaim directly connect to the other though, there’s literally no traffic flowing in it.
why does it matter?
While it’s cool to have the ability to do so, I think there are some reasons why we should do it:
- enabling use cases that are currently not suited
- nicely scaling the transmission rate w/out bottlenecks
- avoiding blocking issues on bad networking conditions
It can really enable certain scenarios that would just not work well before -
where you have a big seggregation between where workers and web instances live
(e.g., web nodes close the where the database live - “In ThE ClOuD” -, and
workers on those beefy machine ‘OnPrEm’):
ThE ClOuD on-prem
k8s something
web1 beefy-super-highcpu-worker-1
web2 beefy-super-highcpu-worker-2
beefy-super-highcpu-worker-3
beefy-super-highcpu-worker-4
beefy-super-highcpu-worker-5
With the workers all sitting on the same DC, they would just stream directly between them, having no heavy traffic going all the way up to the cloud.
Also, comparing this scheme with solutions where a single blobstore exists, streaming seems to make a lot of sense: no waiting for an entire upload to finish before being able to have that consumed, and a nice distribution of work: those who need content, just get directly from the diverse pool of providers.
One last reason that I think might be very considerable here (did not validate), is that on networks where connectivity is “not great” (such a lose definition, I know), because we have all of the connections being multiplexed in a single TCP one, TCP head-of-line blocking can come into play here.
closing thoughts
It’s pretty cool how easy we made to have workers from any network joining the cluster, regardless of where they are.
That for me is such a powerful thing that I can imagine people appreciating a lot - the simplicity of it is just amazing.
On the streaming side, it was pretty cool to do some research on p2p (which I know very little, and would be interested on knowing more about) - seeing projects like dragonfly was pretty cool.