Hey,
I’ve been trying to put myself in the skin of project managers this week and started thinking about some questions related to managing GitHub-based projects. Just trying to grasp what the experience would look like if I needed to gather answers to some very fundamental questions about how my team performs.
The conclusion that came out from this is that project managers might be having a hard time with GitHub.
I see that there are all these tools like ZenHub and CodeTree, but I still don’t see them as great solutions for reporting team activity.
They help when it comes to tracking issues and organizing them, but I have the impression that they can’t go much farther from that (don’t get me wrong, I think it is okay! they do a great job at what they propose).
To get a sense of what’s missing, I started thinking about a project.
What is the project?
Having a very active GitHub user, I know pretty well that there’s a bunch of repositories that, to be honest, I don’t even care, they’re not meant to be tracked, and their activities don’t matter at all.
It turns out that this is also the same for companies - some repositories that are just “lab” experiments, others are quick demos, and some forks were used to contribute to other repositories. No big deal.
Except that it might get in the way when looking for all the GitHub activity across all the repositories.
Can I track just some repositories of all of those that my organization has in GitHub?
Let’s define our project as a set of repositories from all the repositories that our GitHub organization has (it could also aggregate repositories from other organizations).

Think of our project as the intersection of an open source (OSS) only GitHub organization (which has all the repositories public) and a private organization with only private repositories. As I said, not all of them matter and the same is valid for the public ones.
What is the status of our project?
As someone who’s shipping some binaries and that has continuous integration (CI) systems tied to my repositories, it’d be handy to get a sense of how things are going.
Say that github.com/myorg has to release github.com/myorg/docker-image as a Docker image. How can we, in a glance, know whether the current branch is in good shape to be released? I.e., that all the tests pass and that the image is built just fine?
We’ve been doing this forever adding to our README.md a badge that tells people what’s the status of all these sorts of things. I discover a repository out there and then boom, it’s all there.
When you’re at project management though, that’s not how it works (I suppose).
What was the last release of the project repositories?
That’s easy, you might say. Jump to the repository and go to the releases page.
For sure, you can do that. What about when you have 13 repositories and need to make sure things are on track?
What’s the status? Are we green in all master branches? Are the tests falling all the time?
Could I obtain this information from Travis-CI, or maybe Circle-CI? Well, again, sure! However, it turns out that sometimes there’s also Jenkins. Occasionally, other systems advertise their status to commits and pull requests.
Why should I log into each of them just to get a view of the status of the repositories that they’re taking care?
Let’s say GitHub suddenly adds status and release tags to their repositories visualization.
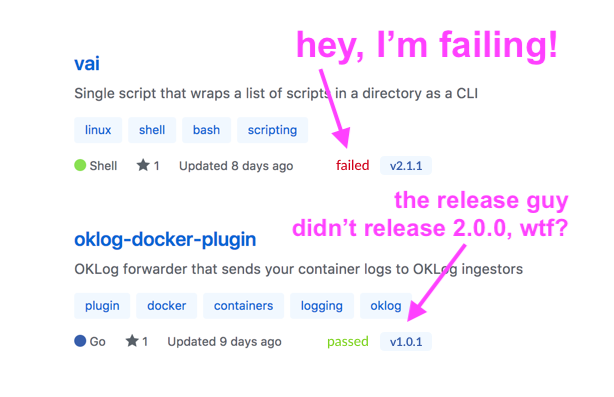
Is that better? Maybe. Does it solve the problem? Well, sometimes, but not ours. Having more than a single organization already brakes the flow of “knowing how things are across multiple organizations.”
Damn, what did I do the whole week?
Monday morning and you go to the standup meeting. Now it’s your time to tell the team what you’ve been working on.
But, wait.
What did I do?
Maybe I’m kinda stupid to not remember things, but I guess there are also some other people out there who just forgive what they’ve been working on last week like me. Perhaps my head goes blank on a topic when I finish working on it, but, who knows? Maybe people are alike.
The point here is that even though you have all your work very documented on GitHub (you created issues, your pull requests were very well written and descriptive, you reviewed pull requests …) there’s no easy way to gather that in a concise manner.
Thinking about the team as a whole we can then multiply that by N. Maybe the other person is also missing something that (s)he did and it would be pretty important for me to know (or just interesting, anyway).
The contribution viz
Looking at what GitHub has we can think about its “contribution map”.
It’s interesting for sure but cmon, that does nothing more than should how “hard” (focus on the air quotes) you’ve been working during some days throughout the year.
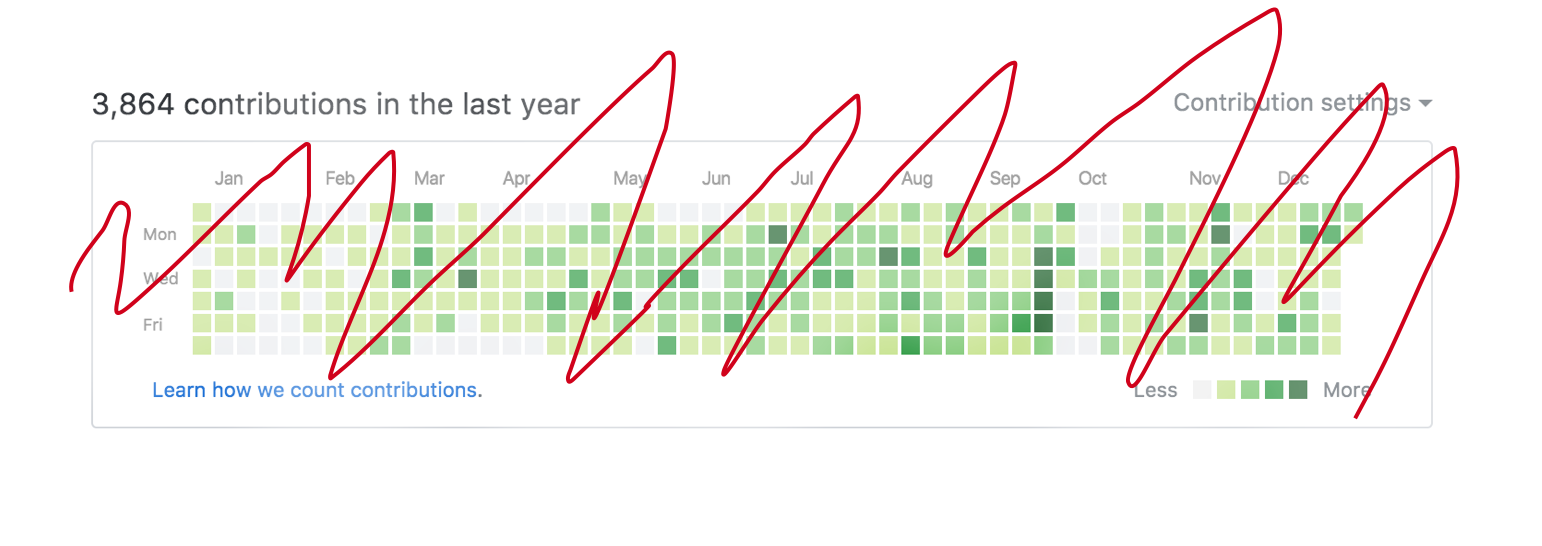
Honestly? It doesn’t bring much to the table.
What were my pull requests about?
Next, we have pull request activity. This one is pretty cool, but there’s a little detail that bugs me:
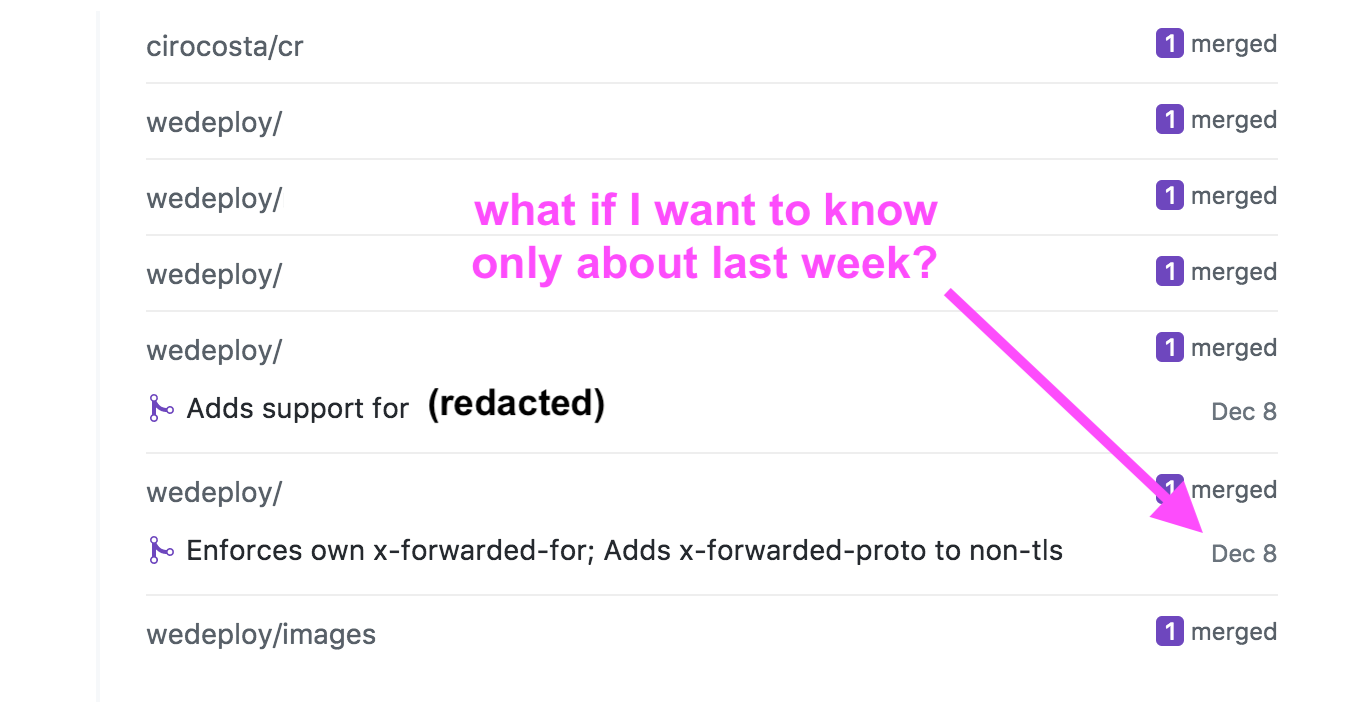
it doesn’t allow me to filter the dates.
What if it’s also essential for me to make sure that my team is having all their pull requests peer-reviewed? What if it matters to know that they’re only getting merged after test passes?
What was I committing?
This topic is a bit controversial in the sense that it might be valid to say that in theory, your commits don’t matter when looking at the high level as every meaningful work would get in the form of pull requests which would be peer-reviewed and tested.
For that reason I think we can come clean out of this.
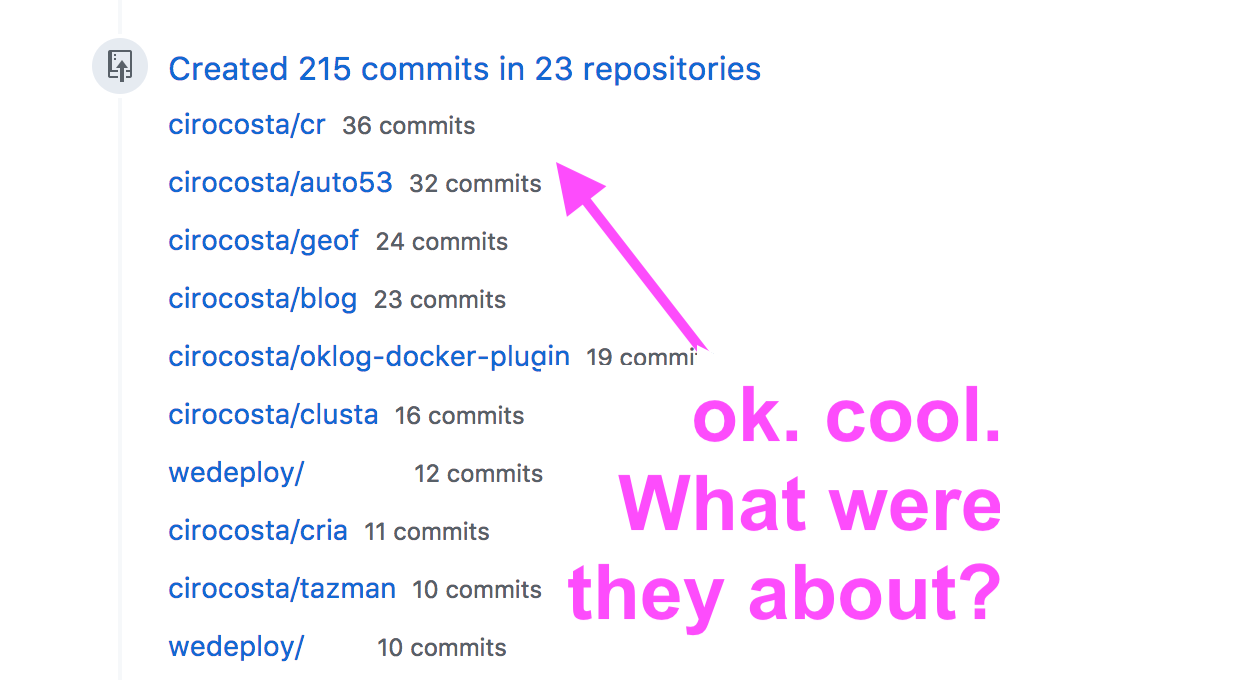
GitHub could let us filter the dates and maybe the status of the CI in each commit … but perhaps it’s not very useful.
Pull request reviews
From time to time I’ve been migrating from just writing code to reviewing a bunch of code.
Even though I’m somewhat new to this, I think this is a place where proper tooling helps.
Right now it’s pretty good to see what you’ve done.
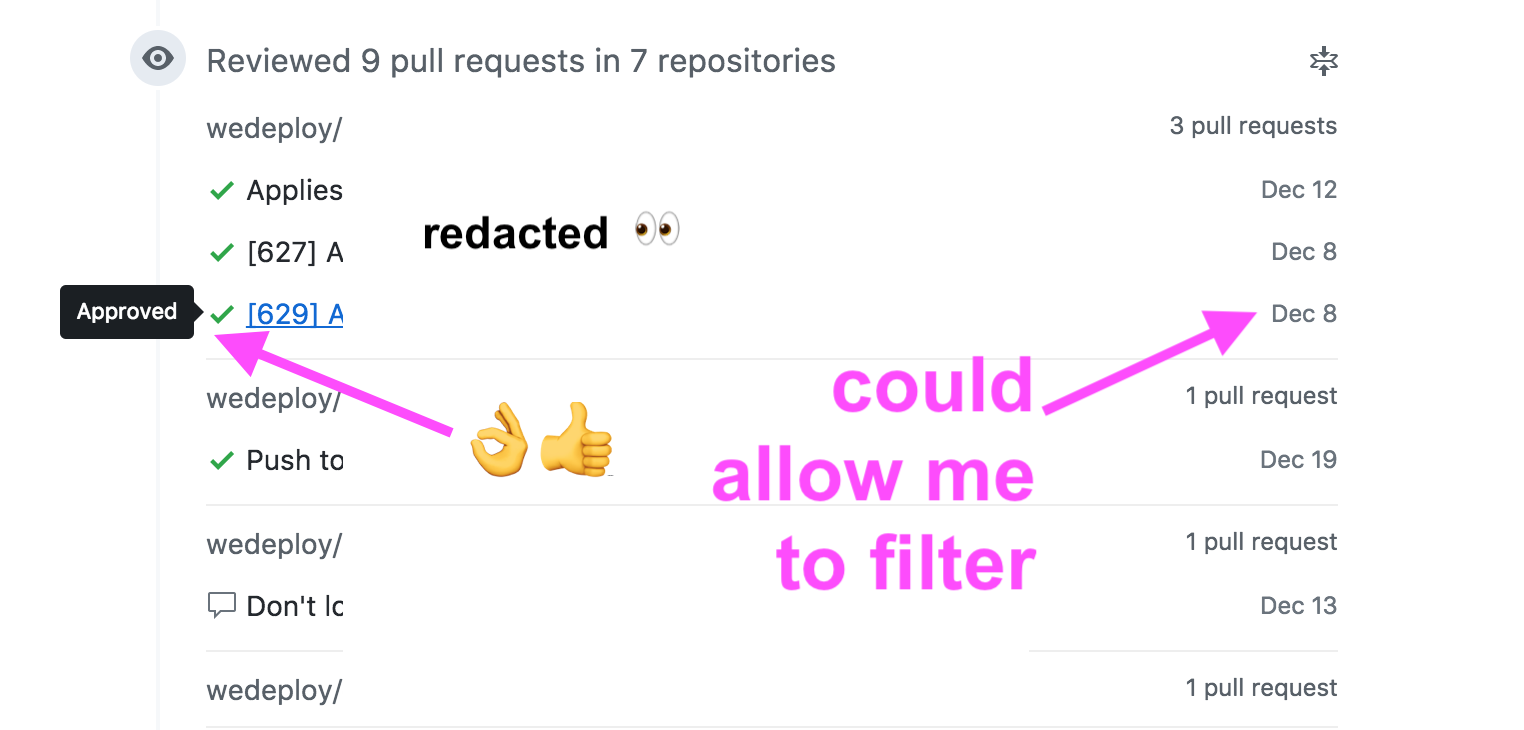
But what about what I have to do?
In some more busier weeks it might happen that I just can’t review the code right away as the notification comes, but I don’t want to have people pinging me (I wouldn’t like to do that to others) and unfortunately GitHub doesn’t make easy for you to see what’s pending very easily when it comes to reviews.
Good good, what’d be cool then?
Sincerely? I don’t know!
I’ve been recentely experimenting with dgraph and it appears to me that indexing GitHub information in a graph database could lead to great answers.
Not that it’s something that you wouldn’t be able to do right now with their REST interface, but it feels like by reducing the difficulty of exploring the relationships between repositories, labels and pull requests, I could maybe ask more interesting questions.
For instance, consider the following schema:
Id: int @index(int) .
Type: string @index(exact) .
Name: string @index(exact) .
Login: string @index(exact) .
ClosedAt: dateTime @index(hour) .
Owner: uid @reverse .
Repository: uid @reverse .
By indexing the repositories, issues, labels and users that are interacting with a repository (say, cirocosta/cr), we could quickly see which labels are the most used querying dgraph with something like:
{
some_query(func: eq(Name, "cr")) {
uid
Name
Issues: ~Repository {
Title
Labels {
Name
}
}
}
}
which gives us back:
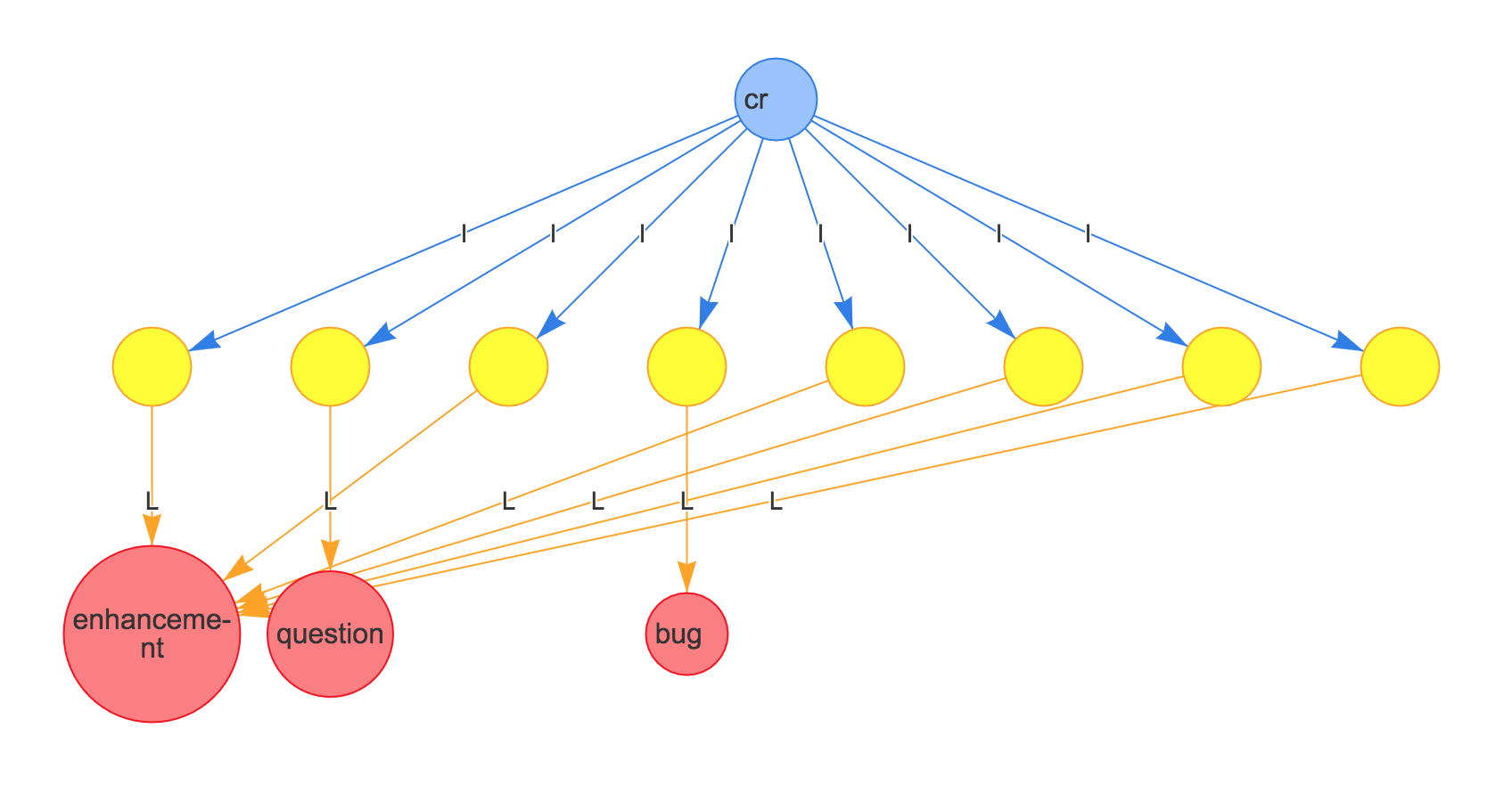
Interesting? Well, maybe. I have the impression that the most interesting is the possibility - have better ways of asking those questions and not being bottlenecked at the retrieval.
My goal is to soon be able to perform some sort of survival analysis on this data.
Survival analysis is a branch of statistics for analyzing the expected duration of time until one or more events happen, such as a death in biological organisms and failure in mechanical systems.
The survival function is a function that gives the probability that a patient, device, or another object of interest will survive beyond any given specified time.[1]
In theory, we should try to minimize this number for bugs assuming that we keep the good practice of always submitting issues and marking them correctly. We should also see that those issues labeled with higher priorities should get lower values (indicating that they “survive” less, in the sense that they get closed soon).
With this kind of calculation we could then estimate the expected amount of time that an issue marked with a given label takes to get into the “death state” (closed).
Closing thoughts
I see that there are many tools that can soon emerge to make querying GitHub data better. The information is there, being produced daily and with great quality. It looks like it’s a matter of exploring it better.
Do share these impressions? Are you using a tool to auxiliate your team gather more insights into how it’s operating?
What would make you improve by knowing data from your development team?
I’d love to hear from you! I’m cirowrc on Twitter, feel free to drop a message there!
Have a good one,
finnis