Hey,
since some months ago I’ve been struggling a bit with the amount of information that I consume in a single day.
It’s just outrageous that sometimes I’d put myself in a zombie mode and just keep following news (even if something like HackerNews which, in theory, should be a good source of interesting information) for so long and not really produce much. I decided to try blocking all these sources for a while and see how it goes.
To do so, I looked for some Chrome extensions that would do the job.
There are several of them out there, as you might expect, but why not give a try implementing it? I’d learn something new (and procrastinate with a “reason”).
td;dr: check out this example: https://developer.chrome.com/extensions/webRequest#examples.
Capturing HTTP requests
Having worked with Firefox extensions before, I knew this couldn’t be all that hard.
From the several Javascript APIs for extensions that are out there, there’s one that is very suitable for our needs: webRequest (yeah, I’m linking to MDN - nowadays the Firefox extension ecosystem uses the same standardized APIs as Chrome does).
From the description of it:
Use the chrome.webRequest API to observe and analyze traffic and to intercept, block, or modify requests in-flight.
Exactly what we need.
Given an HTTP request initiated by the browser we can use this API to mess with it at any point in the request pipeline:
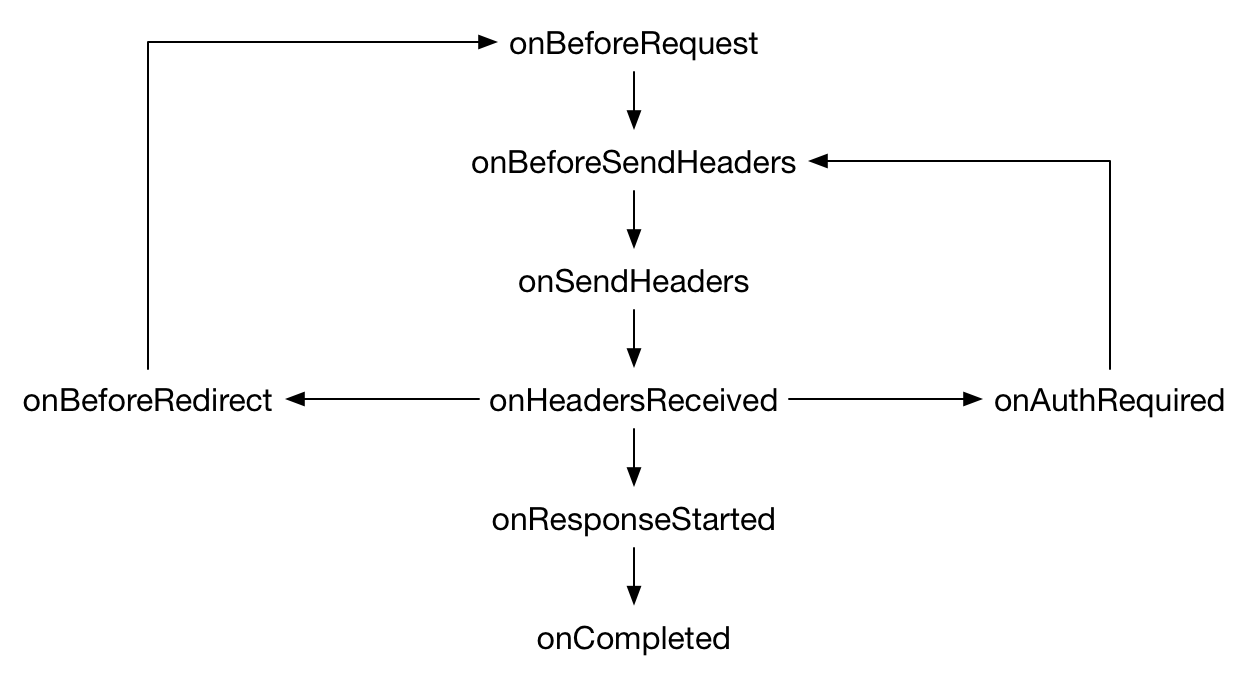
image from MDN: https://developer.mozilla.org/en-US/Add-ons/WebExtensions/API/webRequest
Because we’re aiming at blocking a specific set of requests we can pick the very first one: onBeforeRequest.
onBeforeRequest (optionally synchronous) fires when a request is about to occur. This event is sent before any TCP connection is made and can be used to cancel or redirect requests. (https://developer.chrome.com/extensions/webRequest)
In practice, that means adding the following to a javascript file:
// Limit the requests for which events are
// triggered.
//
// This allos us to have our code being executed
// only when the following URLs are matched.
//
// ps.: if we were going to dynamically set the
// URLs to be matched (used a configuration
// page, for example) we'd then specify the
// wildcard <all_urls> and then do the filtering
// ourselves.
const filter = {
urls: [
'*://news.ycombinator.com/*',
],
}
// Extra flags for the `onBeforeRequest` event.
//
// Here we're specifying that we want our callback
// function to be executed synchronously such that
// the request remains blocked until the callback
// function returns (having our filtering taking
// effect).
const webRequestFlags = [
'blocking',
];
// Register our function that takes action when a request
// is initiated and matches the provided filter that we
// specified in the options.
//
// Because we outsourced the URL filtering to chrome itself
// all we need to do here is always cancel the request (as
// it matches the filter of unwanted webpages).
window.chrome.webRequest.onBeforeRequest.addListener(
page => {
console.log('page blocked - ' + page.url);
return {
cancel: true,
};
},
filter,
webRequestFlags,
);
The functionality can be illustrated as follows:

That’s it!
Closing thoughts
It’s pretty evident that this isn’t suitable for the case where you want to change the list of URLs to the blacklist regularly. There’s a reason why: I don’t keep changing the source of my distractions (lol).
Another point to be made is that it’s effortless to get rid of it: just remove the extension. The rationale for not putting much thought into making it hard to remove is that when impulsively visiting a website like Twitter I’m not totally freaking out of control of myself - I just got into the habit and by breaking the cycle I can stop it (this comes from the great book The Power of Habit).
If you have any questions, just drop by Twitter and let me know - I’m @cirowrc there. You can also subscribe to the mailing list below to receive some up to date content from time to time.
Have a nice one!
finis