Hey,
When Docker Swarm mode got announced, one of the big features included was the routing mesh.
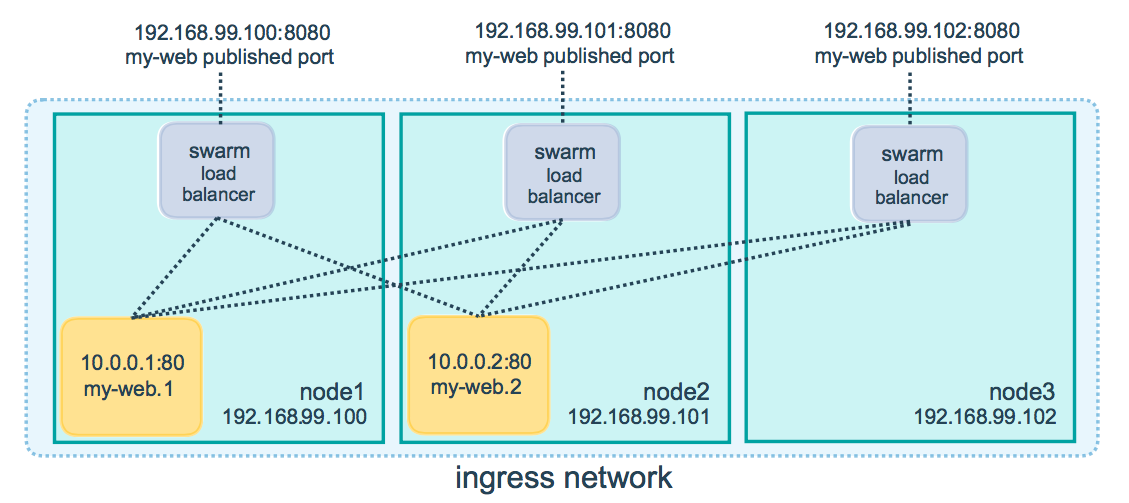
Image from docs.docker.com
Although the feature indeed works as expected, there’s the possibility that you might not want to have all of your nodes accepting connections and performing the job of a load-balancer.

In this blog post, I go through what are the fundamental blocks that the routing mesh uses under the hood so we can block such kind of traffic on specific machines.
The ingress load-balancing setup lifecycle
Given a cluster of machines, whenever a service publishes a port, any machine can be targetted at such port, and an internal load-balancer (IPVS) will send the traffic to a host containing an instance of such service.
For instance, assume that we have the following service definition:
version: '3.2'
services:
nginx:
image: 'nginx:alpine'
ports:
- '8000:80'
deploy:
replicas: 1
And that we have three machines: worker-1, worker-2 and manager.
Once the service is pushed to a Docker Swarm manager, it gets the service instantiated in the form of tasks - only one in this case (replicas == 1)-, which turns into a container in a machine chosen by the manager.
Having a port published (target=80,published=8000), Swarm proceeds with the configuration of the routing mesh, which happens at two moments:
-
at the time that the service gets created, all participating nodes in the cluster set up their IPVS configuration to have a virtual server listening on port
8000. -
at the moment the task lands in a node and a container is created, then all machines update their IPVS configuration again, but now to include a real server that corresponds to the machine in which the container landed, forming the mesh.

Each machine now has the published port (8000) set to listen for incoming connections so that you can target any of them and have the connection adequately established to a container.
If it happens that the nginx container dies and the scheduler (Docker Swarm) creates a task for placing the container somewhere else, or it happens that we have a scale out situation (increasing the number of replicas to two, for instance), all machines become aware of that and update their IPVS configurations.
If the service is removed (or a published port gets unpublished), then again, all participants get to know the change in the overall state and then reflect such changes in their local IPVS configuration.
Under the hood - how Ingress gets traffic directed to containers
If at this point you’ve tried to see how IPVS gets set up, you might’ve noticed that nothing shows up by running ipvsadm --list.
That’s because such configuration is isolated in a namespace (ingress_sbox), and to have a full understanding of how the packet flow looks like, we need to take a look at the iptables rules set in the default namespace to make those packets get into the ingress namespace which is then responsible for doing the whole load-balancing.

To do so, let’s assume a more straightforward scenario:
- there are two machines (
machine1andmachine2), both members of the swarm cluster (it doesn’t matter which one is the manager); - there’s a
nginxservice deployed (publishing port 8000 for the target port 80), having the one (and only one) replica landed inmachine1; and - we’re reaching the nginx service from
machine2.
When the packet gets received by the machine, its device issues an interrupt. A driver that has registered itself as a handler for that takes the packet data from the device (via direct memory access - DMA) and then fills the proper kernel representation of it in its driver (skb). After this, the packet starts flowing through a series of steps in the kernel before it’s sent to a local application or forwarded to a different interface.
One of these steps is passing the packet through the kernel firewall, which can be configured from userspace using iptables (and many others), allowing you to set rules that can do all sorts of packet mangling, filtering, forwarding and more.

These rules that we specify are placed in either preconfigured chains - hooks in the packet flow that are activated at certain points - or custom ones that we can reference from those that are preconfigured.
These chains live under tables, which aggregate a set of chains by their purpose.
For now, let’s focus on the nat table - the table where rules are set to implement network address translation. From the man page:
nat: This table is consulted when a packet
that creates a new connection is encountered.
It consists of four built-ins:
- PREROUTING (for altering packets as soon as they come in),
- INPUT (for altering packets destined for local sockets),
- OUTPUT (for altering locally-generated packets before routing), and
- POSTROUTING (for altering packets as they are about to go out).
Being even more specific, let’s focus on the PREROUTING chain and those chains that are referenced there:
tip: As a way of quickly grasping over all the additions to iptables that Docker made, I like to run iptables-save so we can see all that’s set across all tables.
# List all the chains from the NAT table (by default,
# iptables lists the chains from the FILTER table).
iptables --list --table nat
# As the packet has not been generated in our machine,
# packets get to this chain first before a routing
# decision is taken (i.e., before it's either set that
# the packet is indeed for this machine - INPUT - or that
# it's meant to be sent to another machine - FORWARD).
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
# Using the `addrtype` iptables extension, it looks at
# the packets and then performs matching based on its
# destination address type.
#
# When this rule was set, it was configured to match the
# address type of the destination address to LOCAL - a
# local address.
#
# ps.: LOCAL does not mean only 127.0.0.0/8 CIDR used for
# loopback addresses, but any address that represents the
# local machine (as per the routing table).
DOCKER-INGRESS all -- anywhere anywhere ADDRTYPE match dst-type LOCAL
DOCKER all -- anywhere anywhere ADDRTYPE match dst-type LOCAL
Chain DOCKER-INGRESS (2 references)
target prot opt source destination
# Matches packets that make use of the TCP protocol and
# that are targetted towards port 8000, applying `DNAT`ing
# to them, effectively substituting the destination address
# to 172.18.0.2.
DNAT tcp -- anywhere anywhere tcp dpt:8000 to:172.18.0.2:8000
RETURN all -- anywhere anywhere
Chain DOCKER (2 references)
target prot opt source destination

Now, taking a quick look at ip addr (lists all the devices in the current network namespace together with their addresses), we can notice that such ip (172.18.0.2) must belong to the device connected to the docker_gwbridge bridge:
# Verify that the `docker_gwbridge` interface that belongs
# to the bridge device is indeed the gateway for the 172.18.0.1/16
# network.
ip addr show docker_gwbridge
13: docker_gwbridge: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:af:92:92:f6 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.1/16 brd 172.18.255.255 scope global docker_gwbridge
valid_lft forever preferred_lft forever
inet6 fe80::42:afff:fe92:92f6/64 scope link
valid_lft forever preferred_lft forever
# Check which interfaces have been connected to this bridge.
bridge link show docker_gwbridge
25: veth79f1181 state UP @if24: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master docker_gwbridge state forwarding priority 32 cost 2
29: veth8aec496 state UP @if28: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master docker_gwbridge state forwarding priority 32 cost 2
# We can see that there are two veth pairs connected to it.
#
# Naturally, being veth pairs, from this network namespace we can see
# one side of the pairs, while the other side have their interfaces in
# different network namespaces.
#
# We can corroborate the hypothesis that there exists at least two different
# namespaces by checking that under the hood the `docker_gwbridge` docker network
# has two hidden containers:
docker network inspect \
--format '{{ json .Containers }}' \
docker_gwbridge | jq
{
"ddf1af4f39efaeb556964351800f282aca75d509537d166ff78d5d12b8911cef": {
"Name": "gateway_ddf1af4f39ef",
"EndpointID": "5903ff858bc2d5...",
"MacAddress": "02:42:ac:12:00:03",
"IPv4Address": "172.18.0.3/16",
"IPv6Address": ""
},
"ingress-sbox": {
"Name": "gateway_ingress-sbox",
"EndpointID": "650cc71d444f...",
"MacAddress": "02:42:ac:12:00:02",
"IPv4Address": "172.18.0.2/16", # <<< the ip we saw!
"IPv6Address": ""
}
}
# Get inside this container and see what's going on there when
# it comes to IPVS.
nsenter \
--net=/var/run/docker/netns/ingress_sbox \
ipvsadm --list --numeric
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
FWM 257 rr
-> 10.255.0.6:0 Masq 1 0 0
# Translating that output to pure English, it means:
# - for those connections marked with the firewall mark 257, load-balance
# them using NAT (masquerading) between the list of servers below (given
# that we have a single replica, there's only one address there).
#
# To understand where that IP address comes from, get into the nginx
# container and check its interfaces:
docker exec $NGINX_CONTAINER_ID ip addr show eth0
26: eth0@if27: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue state UP
link/ether 02:42:0a:ff:00:04 brd ff:ff:ff:ff:ff:ff
inet 10.255.0.4/16 brd 10.255.255.255 scope global eth0
valid_lft forever preferred_lft forever
# Now if you're wondering where this network comes from, checkout
# `docker network ls` and inspect the `ingress` network:
docker network inspect ingress --format '{{ json .IPAM }}' | jq
{
"Driver": "default",
"Options": null,
"Config": [
{
"Subnet": "10.255.0.0/16",
"Gateway": "10.255.0.1"
}
]
}
The last thing that’s missing understanding from the ingress sandbox is: how does fwmark (firewall mark) that IPVS uses gets set? The answer is, one more time, iptables.
However, the difference now is that this gets set in the mangle table:
# Get inside the `ingress_sbox` namespace and then issue
# the iptables command to list the chains and rules that
# are set in the `mangle` table.
nsenter \
--net=/var/run/docker/netns/ingress_sbox \
iptables --list --table mangle
Chain PREROUTING (policy ACCEPT)
target prot src dst
# For every packet that is destined to port 8000 (the
# nginx' published port), set the firewall mark to 0x101).
MARK tcp any any dpt:8000 MARK set 0x101
Chain OUTPUT (policy ACCEPT)
# For every packet that is destined to a virtual IP that swarm
# assigns to a specific service (10.255.0.3), also mark the packet
# with the corresponding virtual service mark.
#
# Given that this destination (10.255.0.3) lives in the ingress
# network, this is only accessible from within a container.
target prot opt source destination
MARK all -- anywhere 10.255.0.3 MARK set 0x101
# Given that in iptables that value is set in its hexadecimal
# form, we can look at what 0x101 means in the decimal form
# (shown in the `ipvsadm` listing).
printf "%d\n" 0x101
257
By looking at the man page of iptables-extensions we can see what that target does:
“MARK - This target is used to set the Netfilter mark value associated with the packet.”
And then, looking at ipvsadm man page we can also check how it can make use of such mark:
“Using firewall-mark virtual services provides a convenient method of grouping together different IP addresses, ports, and protocols into a single virtual service. This is use‐ ful for both simplifying configuration if a large number of virtual services are required and grouping persistence across what would otherwise be multiple virtual ser‐ vices.”

In summary, what goes on is:
- A packet is destined for our machine (
192.168.10.4); then - if it’s destination port matches a published port, we take the original destination address (our machine address) and replace it by a different address (
172.18.0.2). As this is performed before a routing decision has been made, it has the effect of making the packet be routed to thegateway_ingress-sboxcontainer that contains the IPVS load-balancer rules. - once the packet lands in
ingress_sbox, it passes through its own iptables rules. This time, it goes through themangletable, which (in the case of being targetted at port 8000), has the effect of adding a marker to the packet (fwmark). - landing in its destination (ipvs), the packet’s fwmark indicates the service that the packet needs to be load-balancer to. IPVS then picks one of the target real servers (using a given scheduling algorithm - roundrobin in this case) and then forwards it to the destination.
- As the destination servers are in the
ingressnetworks, the overlay setup takes care of making the packets reach the destination address accordingly.
Changing IPTables to block Ingress traffic
Having some idea of what goes on under the scenes, we can now jump into the process of putting barriers in the middle of these steps such that traffic can’t go through.
Looking at the last two images, we can imagine that we can either put a barrier between eth0 and ingress_sbox, or we can but a barrier between ingress_sbox and ipvs

If we perform the first block (cut traffic between eth0 and ingress_sbox), then we’re going to be blocking connections that are made from one machine to the physical interface of another, but we’d still allow traffic originating in the host itself.
Taking the second approach looks like a more protective block.
Let’s create some services and some networks and apply the block to see that in action.
# Create a network named `mynet` that uses the
# overlay network driver.
docker network create \
--driver overlay \
mynet
# Create two services in the same network:
#
# 1. nginx1 that specifies a public port mapping
# 8123 --> 80
#
# 2. nginx2 that specifies a public port mapping
# 8124 --> 80
docker service create \
--detach \
--no-resolve-image \
--network mynet \
--publish 8123:80 \
--name nginx1 \
nginx:alpine
docker service create \
--detach \
--no-resolve-image \
--network mynet \
--publish 8124:80 \
--name nginx2 \
nginx:alpine
# Create the `CURL_ARGS` variable that is going to
# hold the non-positional arguments that we'll be
# using throughout the example.
#
# --connect-timeout: specifies the maximum amount of
# time that `connect(2)` should
# take. This is needed because we're
# simply dropping packets.
#
# --silent: removes the verbose curl information
#
# --output: allows us to specify a file that should
# be used as the stdout for the body.
# Using /dev/null we simply discard it.
#
# --write-out: allows us to specify a template of text
# containing information regarding the
# connection / request. By specifying
# %{http_code} we can display the HTTP status
# code of the request (000) on connection
# failures.
CURL_ARGS="--connect-timeout 0.5 \
--silent \
--write-out '%{http_code}' \
--output /dev/null"
# Verify that both of the services can be
# reached from machine1 by targetting its
# own loopback interface.
curl $CURL_ARGS \
localhost:8123
200
curl $CURL_ARGS \
localhost:8124
200
# Get into machine2 and verify
# that it can indeed connect to the
# services by targetting the machine's
# interface (eth0).
ssh ubuntu@machine2
machine2 $ curl $CURL_ARGS \
machine1:8123
200
machine2 $ curl $CURL_ARGS \
machine2:8124
200
# Still in machine2, verify that the
# service is accessible in its own IPVS
# load-balancer by trying to reach the
# service making a request to its own loopback
# interface.
machine2 $ curl $CURL_ARGS \
localhost:8123
200
machine2 $ curl $CURL_ARGS \
localhost:8124
200
# Get back to machine1.
exit
# Get into the `ingress_sbox` network namespace.
#
# To do this we can either make use of `nsenter`
# like we did before or make use of `ip netns` which
# assumes that the network namespace files live under
# /var/run/netns.
#
# As docker creates its network namespace files under
# /var/run/docker/netns, we can get over such default
# by creating a soft link.
ln -s /var/run/docker/netns /var/run/netns
# Given that Docker doesn't make use of the `filter`
# table and doesn't change it at all during service
# changes, we can include specific rules in specific chains
# there to drop desired connections.
#
# By including a rule in the INPUT table, we're able to
# filter packets that are destined to a local address that
# represents the current machine.
ip netns exec ingress_sbox \
iptables -A INPUT -p tcp -m tcp --dport 8123 -j DROP
# Verify that the `nginx` (8123) can't be
# accessed by touching `machine1` ports
curl $CURL_ARGS \
localhost:8123
000
curl $CURL_ARGS \
machine1:8123
000
# Verify that when targetting machine2, the service is
# available:
curl $CURL_ARGS \
machine2:8123
200
# Get into machine2 and verify that it can't access
# the service by targetting machine1
ssh ubuntu@machine2
machine2 $ curl $CURL_ARGS \
machine1:8123
000
# But that it can access it via itself
machine2 $ curl $CURL_ARGS \
localhost:8123
200
# Go back to machine1 (manager) and create a new
# service and verify that docker didn't mess with
# the `ingress_sbox` rules:
docker service create \
--detach \
--no-resolve-image \
--network mynet \
--publish 8125:80 \
--name nginx3 \
nginx:alpine
# Verify that it still fails (which is what we expect)
curl $CURL_ARGS \
localhost:8123
000
Closing thoughts
It was very interesting to go through all of this as a way of learning how to set up a simple block for a given set of ports that wouldn’t mess with the default ingress load-balancing and other Docker-specific chains.
Please let me know if I got something wrong - I’m new to networking and going through this definitely helped me improve and I’d appreciate a lot to be corrected if I presented a misleading or completely wrong information here.
You can reach me at cirowrc on Twitter!
Have a good one!
finis